Coinbase Exchange Architecture: What the May 2026 Outage Revealed

On May 8, 2026, Coinbase halted trading and entered cancel-only mode for approximately seven hours, after a thermal event in AWS US-EAST-1 caused cascading infrastructure failures. The incident exposed a deeper reality about centralized exchanges.
Ultra-low-latency trading systems cannot fail over like conventional cloud applications, and the root cause of such a failure was mundane as well. According to reports, multiple chillers failed at an AWS data center in the US-East-1 region (Availability Zone use1-az4), causing ambient temperatures to rise, leading to hardware failures.
The recovery, however, exposed something more interesting than the failure itself. It laid bare, the architectural structure of a modern centralized exchange and why it shouldn’t be failing, the way conventional cloud services do.
The Architecture
Coinbase operates its centralized exchange on a multi-layered infrastructure with three critical subsystems.
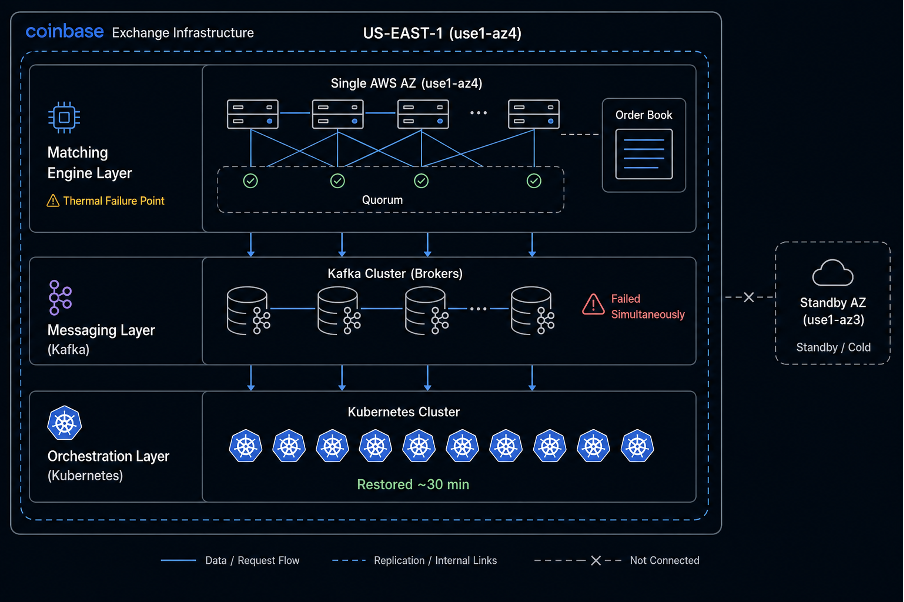
Matching engine layer
The core trading engine runs across a distributed set of servers co-located in a single AWS availability zone. These servers maintain the real-time order book and must maintain quorum, a minimum number of healthy nodes that agree on the system state, to process orders safely. The matching engine uses AWS cluster placement groups to minimize network latency between nodes. This design is deliberate: a trader connected to the same data center sees the fastest execution, and in exchange infrastructure, the trader who submits an order first receives the best available price.
We experienced an outage at Coinbase last night, which is never acceptable. The root cause was a room overheating in an AWS datacenter when multiple chillers failed. We design our services to be redundant to downtime in any one AWS Availability Zone (AZ), and most of our systems…
— Brian Armstrong (@brian_armstrong) May 8, 2026
Messaging layer (Kafka)
Kafka clusters coordinate communication between the matching engine, balance services, and downstream systems. These clusters are designed to remain operational during AZ-level outages, but in this incident, they failed simultaneously as hardware failures cascaded through the environment.
Yesterday @coinbase experienced a multi-hour service disruption affecting trading, exchange access, and balance updates. Here’s our initial read from Coinbase engineering on what happened, how we recovered, and what we’re addressing.
At approximately 23:50 UTC on 2026-05-07, our…
— rob (@rwitoff) May 8, 2026
Orchestration layer
Coinbase reportedly runs approximately 10 Kubernetes clusters to manage workload deployment across its infrastructure. Most of these systems performed as intended during the outage, confirming Armstrong’s statement that most Coinbase systems were designed with AZ redundancy and worked as expected.
Coinbase maintains standby infrastructure distributed across other availability zones. The safeguards designed to isolate failures within the affected zone, however, did not contain the disruption.
What followed was a recovery requiring extensive manual intervention across all three layers simultaneously.
The Cascading Failure
The thermal event triggered simultaneous failures of the matching engine and the Kafka infrastructure. As hardware in the affected AZ degraded, the distributed matching engine lost quorum, meaning it could not guarantee a consistent order book state. Without a quorum, the exchange could not safely process trades.
The Kafka messaging layer that coordinates state across systems also went down, despite built-in resilience for AZ failures. With both the matching engine and the messaging layer offline, engineers faced a recovery requiring the restoration of infrastructure from scratch rather than a failover to a standby system.
The Recovery
Engineers began by draining workloads from the affected Kubernetes clusters to stabilize internal systems. Most services were restored within roughly 30 minutes of diagnosis. But restoring the exchange infrastructure and recovering Kafka partitions required significantly more time under constrained infrastructure conditions.
The recovery followed three stages:
- Restoring cancel-only functionality first, preventing new orders while allowing users to cancel existing ones
- Enabling auction mode for price discovery
- Reopening full trading after validating the exchange state
The process required manual failovers to new hardware brokers and disaster recovery procedures involving terabytes of replicated data. Coinbase confirmed no customer data was lost, though balance updates were delayed throughout the recovery.
Why the Matching Engine Cannot Span Multiple Availability Zones
The matching engine must always see a single, consistent view of the order book. Every buy and sell order needs to be matched against the same state at the same instant. If you run two matching engines in separate availability zones, each one sees a different version of the book. A trader connected to the first zone might see a price of 100, while another trader connected to the second zone might see 101. The first trader buys at 100, but by the time the second zone learns about it, the book is already stale.
This staleness creates an arbitrage opportunity. A trader watching the fresher book can trade against a trader looking at stale prices. The only way to prevent this is to ensure every node sees the same state at the same time, which requires latencies measured in microseconds. Network round-trip times between AWS availability zones typically take one to two milliseconds, which is roughly a thousand times too slow. That is why exchanges colocate their matching engines in a single AZ and accept the failure risk that comes with it.
Implications
Coinbase CEO Brian Armstrong stated that the company would reassess these architectural tradeoffs and seek to reduce the time required to move exchange infrastructure between AZs during failures. The company has not announced specific architectural changes, but the direction is clear — reduce recovery time without sacrificing execution latency.
This is not a Coinbase-specific problem. Every major centralized exchange faces the same tension between latency and resilience. AWS infrastructure continues to concentrate in hyperscale regions, meaning AZ-level failures will continue to affect exchange availability. The industry is actively exploring distributed order book designs that preserve low latency while improving resilience, but no approach has reached production maturity at scale.
For now, exchanges and their users navigate a tradeoff without a clean resolution: execution latency or failover redundancy, but not both at the levels each constituency demands.


